No News is Good News: Using AI to auto skip the news on catch-up radio
Recently, I’ve been expanding my music horizons by listening to radio show recordings rather than relying on algorithm-driven recommendations. While this has been great for discovering new music, there’s one persistent annoyance: outdated news bulletins from the time of broadcast are still present in the recordings. Hearing old news reports can be jarring, and manually skipping them is often imprecise.
What’s really needed is a podcast-style chapter system that would let listeners jump past these sections. However, the current player from the broadcaster is just one continuous stream with no built-in navigation markers, making it impossible to efficiently bypass unwanted content.
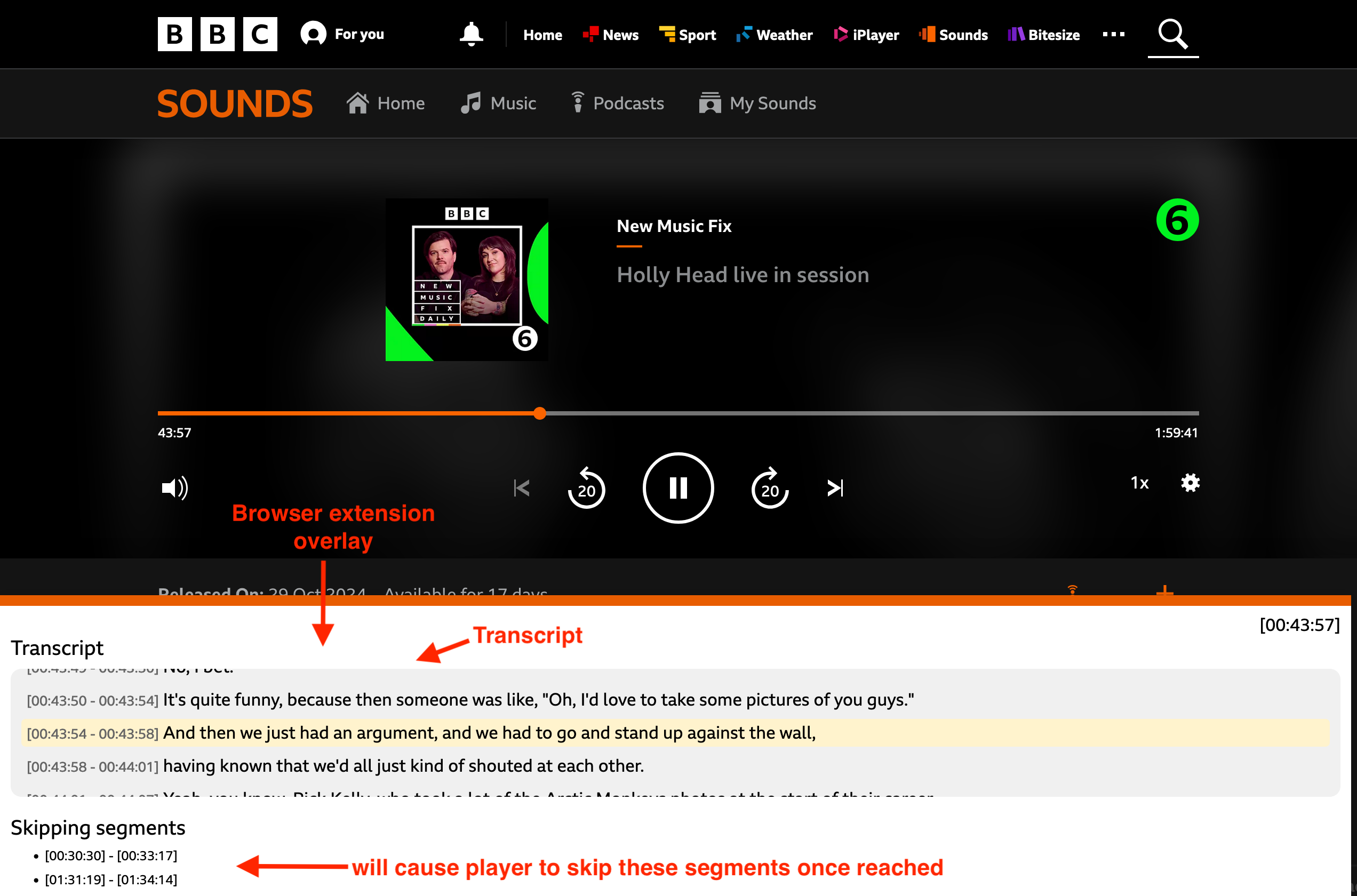
So, with a weekend ahead of me free I went away and built something to auto-skip the news segments when listening. It’s a browser extension that runs on the same page as the player, gets a handle on the <audio> element and skips the news segments when the time is reached, and also includes a bonus feature of scrolling through a transcript of the show.
Now I can listen to the programmes without the scourge of old news ruining it.
How it works
You’ll be disappointed to hear the solution isn’t magic or doing anything fancy. The news segment detection happens in an out of band batch process and the browser extension just takes the output of that to control the player.
player.addEventListener('timeupdate', () => {
this.checkAndSkip(player);
});
seek(player, seconds) {
console.log("Moving to =", seconds);
player.currentTime = seconds;
console.log("New currentTime =", player.currentTime);
}
checkAndSkip(player) {
if (this.skipPoints == null) {
return;
}
// checks if we need to skip the player forward
// if the current time is within a skip point
let currentTime = player.currentTime;
for (let startTime in this.skipPoints["skips"]) {
startTime = parseFloat(startTime);
let endTime = this.skipPoints["skips"][startTime];
// If we're at a skip point (with small buffer for precision)
if (currentTime >= startTime && currentTime < endTime) {
console.log(`Skip point detected, seeking to ${endTime}`);
this.seek(player, endTime);
}
}
}
News Segment Detection
Identifying where news segments begin and end presents a challenge. While others have explored similar problems, like automatically removing radio advertisements through sophisticated digital signal processing (DSP) techniques, these solutions typically rely on audio cues such as jingles or “bookends” to mark segment boundaries. Unfortunately, the shows I listen to don’t use such clear audio markers to indicate news sections.
However, the news does tend to start/end with some words/phrases that could be considered bookends, although it’s unclear how consistent these are across shows and newsreaders.
BBC News at 7.30. This is Anthony Burchly.
…That’s 6 Music News, your next update is at 8.30
So my initial idea was to find some way of getting a transcription of the show to look for these phrases and identify them as segments to skip, e.g. chances are if something opens with “BBC News at…” then within 3-4 minutes there should be a corresponding closing remark to indicate the end of the news segment.
Where does one turn when you have no idea what you are doing and will blindly trust anything? AI of course!
Getting the transcription seemed like a good fit for multi-modal LLMs, but I didn’t feel comfortable uploading shows to the major players because getting the audio requires downloading them through means where it’s probably legally questionable1. I didn’t want to get my AI accounts banned due to uploading copyrighted content2.
I decided instead to use local models, specifically OpenAI’s whisper for speech recognition. After initial testing, I found that switching to whisper.cpp, which offers GPU support, significantly improved performance. This setup allowed me to process audio files at reasonable speeds on my modest M1 Macbook Air.
Whisper.cpp supports outputting the transcript as JSON and they come out looking something like this.
...
{
"timestamps": {
"from": "00:01:52,960",
"to": "00:01:57,040"
},
"offsets": {
"from": 112960,
"to": 117040
},
"text": " Yee-haw, hey music fans, welcome to the
new Music Fix Daily"
},
{
"timestamps": {
"from": "00:01:57,040",
"to": "00:02:02,500"
},
"offsets": {
"from": 117040,
"to": 122500
},
"text": "on BBC six music with Tom and Deb starting the show"
}
...With this in place my first stab was to try and identify the bookends by looking for the phrases I described earlier. This kind of worked ok but wasn’t consistent, e.g. you’d get situations like this
...
{
"text": "BBC"
},
{
"text": "news at"
},
{
"text": "6:30, Sir Kier Starmer has"
}
...Not optimal, and requires much more fooling around looking/forward backwards in the transcript to try to infer where the bookends sit. I was getting fed up around trying to come up with the solution that catches all things.
So where does one turn where they’re fed up of their stupid python script and wants someone else to do something about it? AI of course!
Rather than continue struggling with manual pattern matching, I turned to AI for help. Following some prompt refinements3 and an upgrade from Gemini Flash to Pro, the model proved remarkably effective at identifying news segments.
Prompt:
► This is a transcript from a radio show. Could you please identify the segments in the transcript that are BBC news reports so that I can trim them out
I'd like the output to be in JSON format with no surrounding markdown just pure JSON, here's an example
[
{
"segment":{
"start": "00:33:00",
"end": "00:35:58"
},
"duration_seconds": 178
},
{
"segment":{
"start": "01:13:22",
"end": "01:16:33"
},
"duration_secs": 123
}
]
The model produced something like this.
[
{
"segment": {
"start": "00:29:36",
"end": "00:32:41"
},
"duration_seconds": 185
},
{
"segment": {
"start": "01:29:37",
"end": "01:32:41"
},
"duration_seconds": 184
}
]Whether the model is consistent enough across lots of shows to produce decent results remains unclear, but from the handful I’ve processed so far the results have looked pretty decent.
Putting all the bits together
Having solved the news detection challenge by trusting the output of whatever the AI gives, I created an automated pipeline that handles the entire process: downloading media files for the show by scraping the recordings page, processing them through whisper.cpp, and using Gemini Pro to identify the skip points.
The pipeline then saves both transcriptions and skip timestamps to disk, which are served via a simple server that resolves the programme ID to transcript.
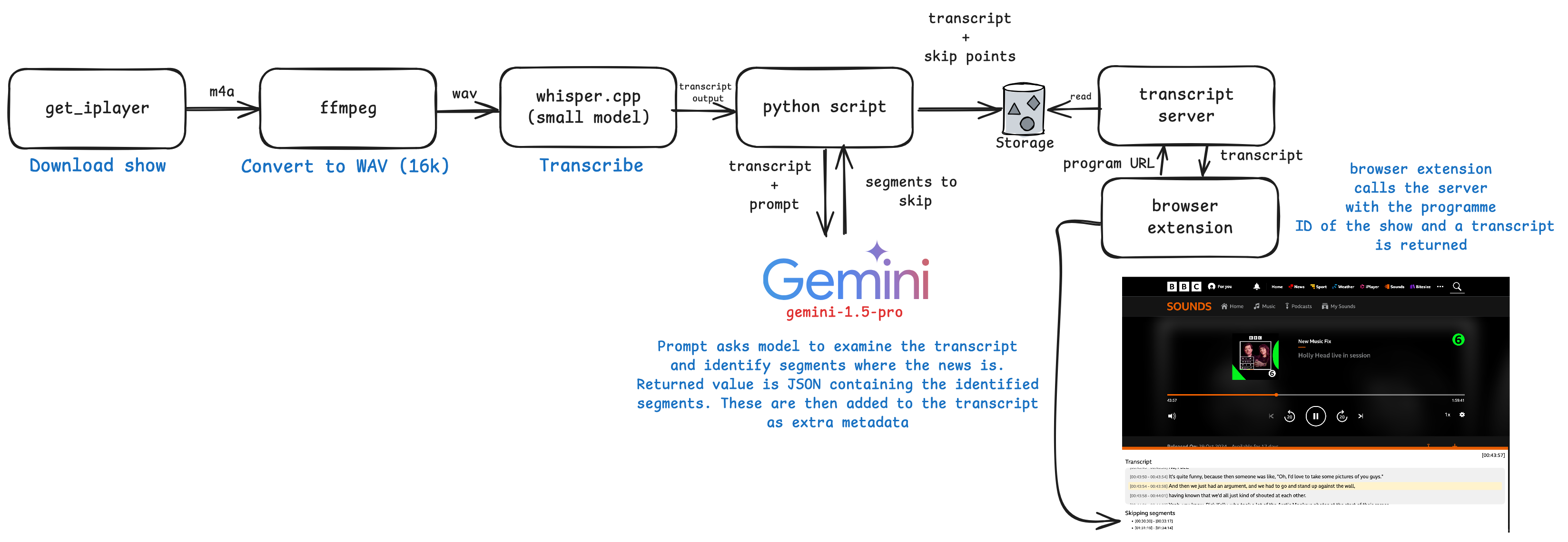
When on the playback page for a show, the browser extension requests the corresponding transcript from the server. It then configures automatic news segment skipping and renders the transcript on the page. The transcript display isn’t essential to the functionality, I just thought it was neat.
I’m not gonna open source this just yet, I wrote the code in a weekend, it’s all a bit thrown together, untested garbage which I don’t apologise for, I built it for a stupid personal grievance.
On reflection
This was a fun project but probably way over engineered for a small use case. Additionally during development it was funny, and in hindsight, unsurprising to find that the news segments are remarkably punctual (around 30 minutes and 90 minutes into the show, each running around 180-190 seconds) so just looking around timestamps with a simpler approach could achieve the same result - but where’s the fun in that?
I also enjoyed writing the browser extension to augment some functionality on an existing website to suit my own needs. I even used LLMs to help me start writing it because I’d never written one before and it always seemed like a faff, but these models got me started so I could have something up and running pretty quickly.
Future ideas if I can be bothered
- Try and find more ‘segments’ in the show e.g. interviews
- Try and identify song boundaries - this is probably harder with transcriptions but I wonder if you just threw the audio file into one of the larger multi-modal LLMs it might be able to do something
Cheers xxx